Статистика и котики
Первое, что мы должны сделать, это сравнить группы до эксперимента. Для этого используются t-критерий Стьюдента для несвязанных выборок или U-критерий Манна-Уитни. Котики при этом не должны различаться. Если в одной из групп котики более здоровы, то это очень плохо, поскольку не позволит четко отследить влияние лекарства.
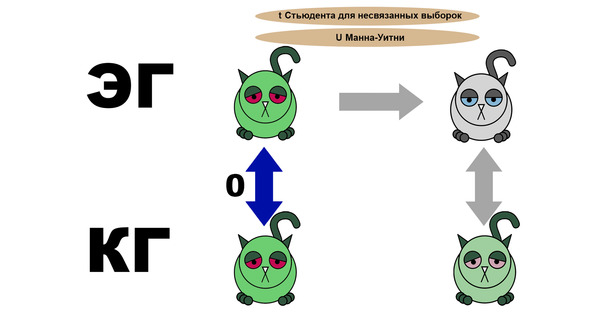
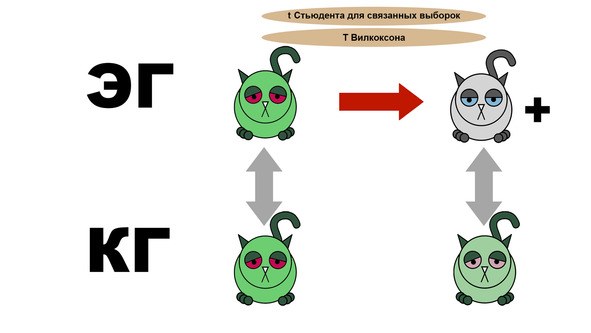
Далее мы сравниваем экспериментальную группу до и после приема лекарств с помощью t Стьюдента для связанных выборок либо T Викоксона. Если различия есть и состояние котиков улучшилось, то мы можем начинать радоваться. Но не сильно. Ведь вполне возможно, что контрольная группа продемонстрировала тот же результат.
Поэтому последним замером мы смотрим, чем отличаются экспериментальная и контрольная группы после приема лекарств. Если различия есть, и экспериментальным котикам гораздо лучше, чем контрольным, то лекарство реально подействовало.
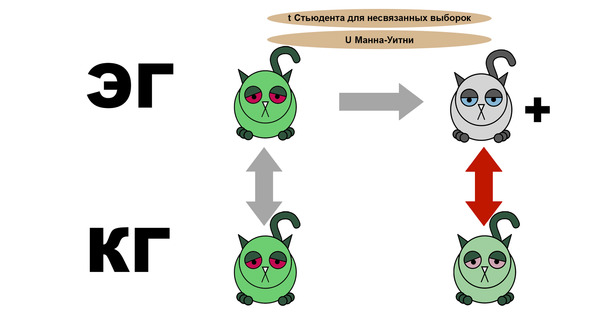
Таким образом, мы можем сделать вывод, что лекарство действует, только если до эксперимента между группами различий нет, после — есть и имеются положительные изменения состояния в экспериментальной и контрольной группах. Прочие варианты указывают либо на неэффективность лекарства, либо на неправильную организацию эксперимента.
Важно отметить следующее: поскольку для проверки эффективности лекарства мы вычисляли три критерия, то здесь возникает проблема множественных сравнений. Чтобы ее преодолеть, необходимо применить поправку Бонферрони и сравнивать p-уровень значимости не с 0,05, а с 0,017. В противном случае вы рискуете очень сильно ошибиться в своих выводах.

Альтернатива этому — использование
Глава 8.
Лечение котиков
или дисперсионный анализ с повторными измерениями
Из предыдущего раздела мы узнали, как определить, помогает ли то или иное лекарство, если ваш котик заболел. Однако, иногда котики болеют тяжело, и им требуется специальное лечение в особых котиковых клиниках. И, как правило, это лечение подразумевает регулярную сдачу анализов, чтобы отслеживать, становится ли котикам лучше.
Когда таких сдач много (а точнее, больше двух), возникает проблема множественных сравнений, о которой мы не раз говорили выше. Если кратко, то она заключается в том, что, если вы будете попарно сравнивать первый анализ со вторым, второй с третьим и т. д., вероятность того, что вы ошибетесь в своих выводах, будет возрастать.
Разрешить эту проблему, как и в предыдущем случае, может дисперсионный анализ, а точнее, его особая разновидность —

В самом простом варианте мы действуем практически так же, как и при обычном дисперсионном анализе: делим дисперсию на части. В тот раз таких частей было две: первая была обусловлена влиянием лечения (межгрупповая дисперсия), а вторая — остальными факторами (внутригрупповая дисперсия).
Однако важным отличием является то, что мы проводим все измерения на одних и тех же котиках. Иными словами, каждый котик измеряется по несколько раз и, соответственно, вносит свой вклад в общую дисперсию. Таким образом, наша дисперсия делится уже на три части: межгрупповую, внутригрупповую и
Критерий Фишера сравнивает между собой только первые два вклада. Соответственно, чем он больше, тем больше причин отклонить нулевую гипотезу. И опять же — если вы отклонили ее, то попарное сравнение нужно будет проводить с помощью специальных post hoc критериев.

У дисперсионного анализа с повторными измерениями есть свой непараметрический брат-близнец —
Идея его достаточно проста. Возьмем одного из котиков, у которого взяли три пробы анализов. Каждой из этих проб мы присваиваем ранг, где один — это самый плохой анализ, а три — самый хороший. То же самое мы делаем и с остальными котиками, получая в итоге вот такую таблицу.
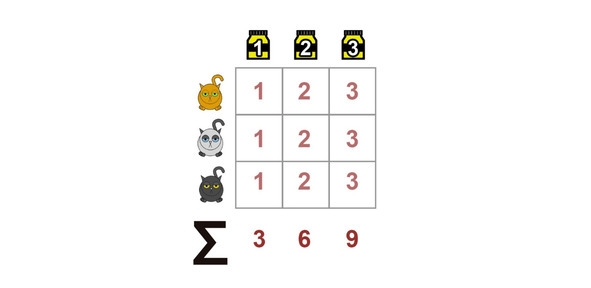
Очевидно, что если первая проба у всех котиков самая плохая, а последняя — самая хорошая, то по итогу суммы рангов будут сильно различаться и нулевая гипотеза будет опровергнута. Обратная ситуация — когда суммы рангов во всех пробах одинаковы. Это будет означать, что лечение никак не повлияло на котиков.
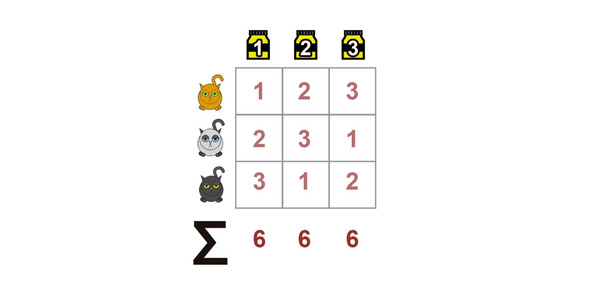
Сам же критерий Фридмана, собственно, и позволяет оценить, насколько различаются эти суммы рангов.
НЕМАЛОВАЖНО ЗНАТЬ!