Статистика и котики
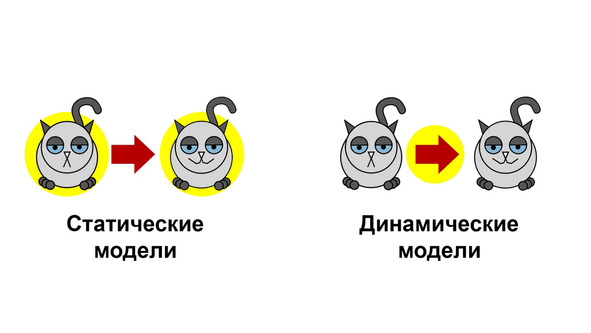
Кроме того, модели делятся на
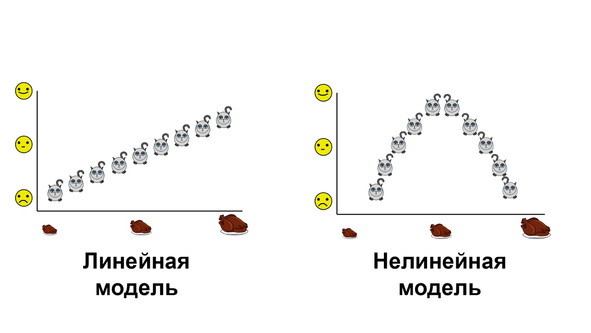
Также имеет смысл рассмотреть деление моделей на
Дискретные же модели работают с переменными, которые имеют ограниченное количество значений. Например, тот же размер, но имеющий только три значения: маленький, средний и большой. Построить модели с дискретными целевыми переменными, в частности, позволяют логистическая регрессия и дискриминантный анализ.
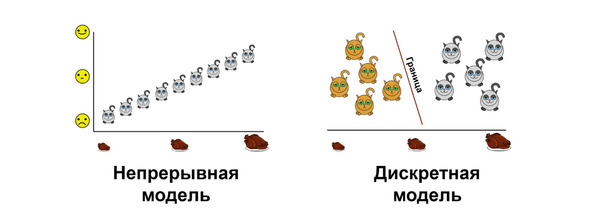
Впрочем, на практике большинство моделей относятся к смешанным типам — в них встречаются как дискретные, так и непрерывные переменные, а линейные взаимосвязи вполне могут сочетаться с нелинейными.
Глава 13. Разновидности котиков
или основы кластерного анализа
Из предыдущих разделов мы узнали, как определить, какие факторы делают наших котиков счастливыми. В этом нам помогли регрессионный и дискриминантный анализы. Зная значения этих факторов, мы можем предсказать, будет ли тот или иной котик счастливым или несчастным. Иными словами, мы можем рассортировать котиков по классам, т. е.

Вообще, задача классификации является крайне важной практически для всех наук, изучающих котиков. Но довольно часто мы не имеем никакого понятия даже о том, на какие группы делятся котики. Ведь котики очень разные. Поэтому существуют методы, которые позволяют не только рассортировывать котиков на группы, но и выделять сами эти группы. И все вместе они называются
В первом приближении у нас могут возникнуть две ситуации. Первая — мы знаем, на сколько групп у нас должны делиться котики, но не имеем понятия, где эти группы находятся. Вторая — мы не знаем итоговое количество групп. Со второго случая мы, пожалуй, и начнем.
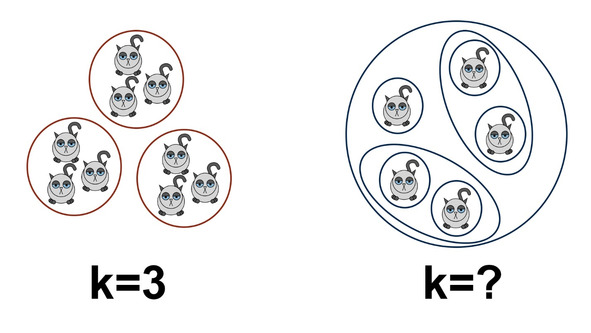
Рассмотрим самый простой пример. Предположим, что мы захотели поделить наших котиков по размеру. Очевидно, что чем больше два котика похожи друг на друга, тем больше шансов, что они окажутся в одной группе. Чтобы понять степень похожести, надо просто найти разность между размерами — чем она меньше, тем более похожими являются наши котики.

Итак, мы вычисляем все возможные разности между размерами котиков. Далее пара самых похожих котиков объединяется в группу (или кластер). Затем мы вновь вычисляем разности. А затем опять объединяем самых похожих. И так происходит до тех пор, пока у нас все котики не объединятся в один большой кластер.
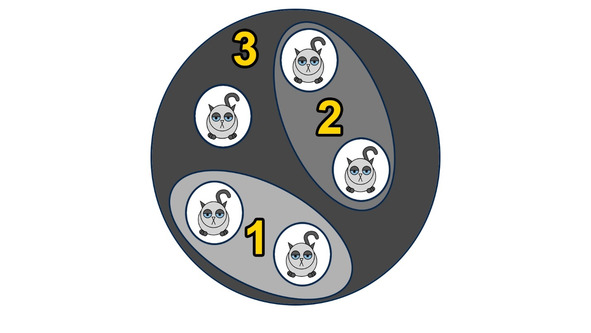
Этот алгоритм относится к методам
1. Эти методы могут работать с большим количеством переменных — вы можете брать и размер, и степень пушистости, и длину коготков, и прочие котиковые признаки одновременно.
2. На основе этих признаков вы вычисляете степень похожести котиков (чаще используется термин
3. Котики последовательно объединяются в группы. Это может происходить так, как было описано выше (так называемый «
4. По итогу вы получаете график, называемый
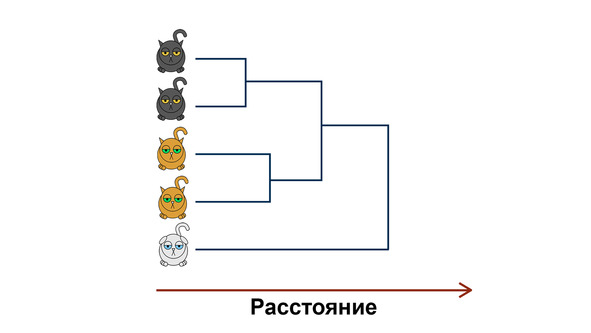
Напомним, что иерархический кластерный анализ позволяет вам разбить котиков на группы, когда вы не знаете, сколько у вас их должно получиться. А если знаете, то более адекватным будет использование метода
Идея достаточно проста. Предположим, вы подозреваете, что все котики делятся на три различающиеся размером группы. Тогда у каждой группы существует свой представитель, который обладает самым типичным для группы размером. Такой котик называется
Происходит это пошагово. На первом этапе мы произвольно расставляем центроиды.
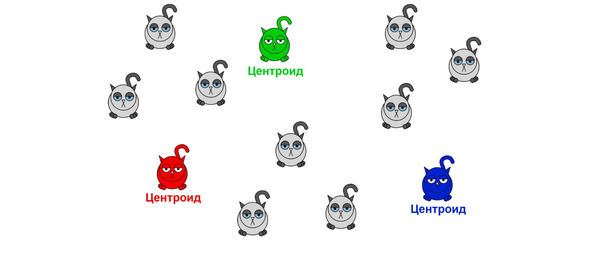
На втором этапе вычисляются расстояния от каждого котика до каждого центроида.