Даже убедительные с научной точки зрения доказательства, такие как пробы ДНК, могут вводить в заблуждение, если статистика представляется некорректно. Например, американской коллегии присяжных на суде об ограблении могут сказать, что вероятность совпадения ДНК подозреваемого и ДНК с места преступления – один на миллион. В результате присяжным может показаться, что дело не стоит и выеденного яйца. Но в США проживает 152 миллиона взрослых мужчин, а значит, помимо подозреваемого может найтись еще 151 человек, ДНК которого совпадет с ДНК преступника. Для вынесения обвинительного вердикта этих улик недостаточно.
Подобная проблема возникла при тестировании населения на COVID-19 в разгар недавней вирусной пандемии. В несовершенном мире нам кажется, что тест, дающий “99 % точности”, близок к совершенству, правда? Значит, нужно применять его ко всем, вне зависимости от того, есть ли у них какие-либо симптомы болезни, так? Если тест окажется положительным, люди вылечатся (при необходимости), а затем вернутся к своим делам, зная, что не заболеют снова, потому что у них сформировался иммунитет. Но такое субъективное решение может привести к ужасным последствиям.
Допустим, один человек из тысячи действительно болен COVID-19, и мы тестируем 1000 человек. На 99 % точный тест даст нам верный ответ при тестировании 99 % больных и 99 % здоровых. Следовательно, он выдаст положительный результат оставшемуся 1 % из 999 человек, которые не болеют коронавирусом. Это огромное число – 9,99 человека. Фактически 11 человек из 1000 получат положительные результаты, но только один из них действительно приобретет иммунитет. Это значит, что если ваш тест показал положительный результат, вы можете быть лишь на 10 % уверены в том, что у вас сформировался иммунитет. Не очень полезно, правда? И это если вы владеете
Такая нелогичность является одной из причин, по которым многие статистики предпочитают работать с другой системой. Она называется байесовской статистикой и появилась довольно давно. Преподобный Томас Байес вывел свою теорему в середине XVIII века. Точной даты мы не знаем, поскольку Байес никогда ни с кем не делился своими идеями.
Байесовская статистика, описанная в документах, обнаруженных после смерти преподобного в 1761 году, по-прежнему вызывает у статистиков споры. Никто не может однозначно сказать, лучше ли она, чем стандартная “частотная” статистика, которую мы разбирали ранее. Знакомая нам система называется частотной, поскольку в ее основе лежит поиск вероятности путем анализа частотности конкретного исхода. Так, если я буду снова и снова бросать правильную кость, в долгосрочной перспективе все числа будут выпадать с одинаковой частотой. Байесовская система, с другой стороны, изучает “условные вероятности”: каковы шансы
Допустим, вы присяжный и вам представили улику, которая на 70 % убедила вас, что я виновен в нападении. Но вас пока не ознакомили с данными судебной экспертизы. Из них вы узнаете, что на жертве найдена кровь такой же группы, что и у меня. Ага! Но постойте: такая группа крови у 35 % населения. Должно ли это повысить вашу уверенность в моей виновности? Или понизить? Или же эта информация не имеет значения?
Вооружившись байесовской статистикой, вы можете прямо на скамье присяжных рассчитать все с помощью карандаша и бумаги. Для меня ваши расчеты обернутся катастрофой: теперь вам следует примерно вдвое сократить свою уверенность в моей невиновности. Это, однако, не значит, что вы уверены в моей виновности на 140 %. Дело обстоит так: вы были на 30 % уверены, что я невиновен, но данные судебной экспертизы укрепили вашу уверенность в том, что я виновен. Теперь вы лишь на 14 % уверены в моей невиновности, а следовательно, на 86 % уверены, что я совершил преступление[192].
Может, вам кажется сомнительным, что присяжному под силу разобраться с числами, чтобы оценить свою уверенность в виновности подсудимого, но уверяю вас, в этом нет ничего нового. Возьмем, например, дело “Нью-Джерси против Спанна” 1993 года[193]. Чернокожего тюремного надзирателя Джозефа Спанна обвинили в зачатии ребенка при совокуплении с заключенной – с учетом его положения это преступление. Все зависело от того, сможет ли обвинение доказать, что Спанн – отец ребенка.
Прокурор представил данные судебной экспертизы на основе генетического тестирования, которое, как утверждалось, с вероятностью 96,55 % показало, что отцом действительно является Спанн. В экспертизе учитывалось, что у ребенка обнаружился определенный набор генов, которого не было в ДНК матери, но который обычно присутствует в ДНК 1 % чернокожих американских мужчин, и что Спанн входил в этот один процент. Присяжным сказали, что им следует отталкиваться от любой “априорной” оценки вероятности его вины, но также сообщили, что государственный свидетель-эксперт присвоил ей “нейтральную” вероятность в 50 %. Весьма любопытно ознакомиться с подробностями этого дела[194]. Эксперт показал, что итоговая вероятность менее чем в 90 % считается “не показательной”, при результате 90–94,99 % отцовство признается “вероятным”, 95–99 % – “весьма вероятным”, а 99,1–99,79 % – “крайне вероятным”.
Присяжным объяснили, как рассчитать свою уверенность на основе выбранной ими априорной оценки. Им, однако, не показали, как априорная вероятность скажется на итоговом результате. В конце концов они признали подсудимого виновным, но это дело остается спорным по целому ряду причин – и не в последнюю очередь потому, что решение зависело от статистических расчетов не сведущих в статистике присяжных.
Если у вас от этих чисел закружилась голова, вы вовсе не одиноки. Сегодня, когда данные судебных экспертиз играют все большую роль в системе правосудия, задействованная в них математика становится весьма проблематичной. Идея о том, что обычные люди решают, виновны ли обвиняемые в преступлениях, формирует фундамент нашего общества, но сложно спорить с тем, что статистику лучше оставить на откуп профессионалам. В следующем рассматриваемом случае – в случае с исследованиями, определяющими судьбу лекарственных средств, – сомневаться в этом не приходится. Давайте с помощью стандартного частотного подхода взглянем на статистику гипотетического испытания лекарственного препарата.
Пока мы не освоили искусство большего, эффективность лечения оценивалась субъективно, часто по слухам или по наитию. Так, например, прославленный гений Исаак Ньютон убедил себя в том, что раствор жабьей рвотной массы лечит бубонную чуму. Сегодня у нас есть более надежные способы. Допустим, мы хотим проверить гипотезу, что лучше принять обезболивающее (назовем его “БезБол”), чем не принимать никаких лекарств или принять плацебо (таблетку, не содержащую действующего вещества). Сначала мы подвергнем всех испытуемых слабому электрическому шоку и попросим их дать оценку боли. Затем мы дадим половине из них “БезБол”, а другой половине – плацебо, которое не отличается от “БезБола” ни видом, ни вкусом, но при этом не обладает обезболивающим действием. Теперь мы снова подвергнем испытуемых электрошоку и попросим их оценить боль. Велика вероятность, что мы получим три характерных нормальных распределения: кривую “БезБола”, кривую плацебо и начальную кривую. Как понять, стоит ли нам пускать “БезБол” в производство?
Нужно провести “проверку гипотезы”. По сути, мы хотим узнать вероятность случайного наступления улучшения. Скажем, начальная средняя оценка боли составила 5,71 (из 10) для 50 испытуемых. Стандартное отклонение в этом наборе данных – 1,97. Группа пациентов, которым дали “БезБол”, сообщает, что боль при электрошоке составила в среднем 4,28 из 10 при стандартном отклонении 1,72. Группа плацебо теперь оценивает боль в 4,80 из 10 при стандартном отклонении 1,42.
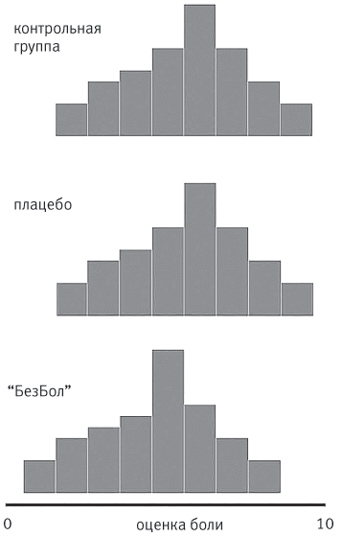
Распределения “БезБола”, контрольной группы и группы плацебо
Теперь можно взять данные по группам “БезБола” и плацебо, подставить их в стандартные статистические формулы и вычислить
Это немного выше 0,05 – обычного стандарта статистической значимости. Поскольку
Хотя история статистики и вызывает у нас вопросы, а необходимость принимать субъективные решения может показаться нам проблематичной, нет смысла отрицать, что в современном мире статистика обрела огромную важность и влияние. Статистические инструменты каждый день используются в медицине, политике, экономике, правосудии и науке. Но одна область статистики оказывает на нашу жизнь гораздо большее воздействие, чем остальные. Я имею в виду семплирование.
Семплирование – это искусство достоверно экстраполировать знания о малой части чего-либо, чтобы получать представление о целом. Вы постоянно прибегаете к семплированию, но действуете, вероятно, по наитию, без математической точности. Так, готовя спагетти, вы наверняка снимаете больше одной пробы, чтобы удостовериться, что блюдо уже можно подавать к столу. Если вы ищете электрика, то что-то подсказывает вам, что лучше сперва спросить в нескольких местах, сколько стоят необходимые работы, чтобы в итоге с вас не взяли слишком много. В процессе онлайн-шопинга вы также принимаете субъективные решения о семплировании, изучая отзывы покупателей: можно ли считать, что продукт, которому поставили пять высших оценок, лучше, чем продукт, который 200 раз оценили на четверку?
В промышленных масштабах ситуация с семплированием не отличается. Если я сорву с поля 10 спелых колосьев ячменя и изучу их качество, насколько показательными будут результаты моей проверки для оценки состояния всего поля? Если я сниму с заводского конвейера 10 деталей и подвергну их испытанию на прочность, насколько я смогу быть уверенным в качестве остатка партии? Есть ли способ выяснить, будет ли лекарство помогать большинству людей, проверив его лишь на нескольких? Если я могу передать лишь небольшую часть сигнала по электрическому или оптоволоконному кабелю, то есть ли способ собрать отправленные мною фрагменты, чтобы человек на другом конце смог воссоздать оригинальное сообщение? Эти вопросы на множество миллионов долларов лежат в основе нашей потребительской экономики.
История семплирования восходит как минимум к 400 году нашей эры. В санскритском эпосе “Махабхарата” древнеиндийский правитель Ритупарна оценивает количество плодов на двух больших ветвях дерева бибхитаки. Сосчитав плоды на нескольких маленьких веточках, он заявляет, что на всем дереве 2095 плодов и 100 тысяч листьев. Его спутник царь Нала всю ночь не смыкает глаз, чтобы проверить ответ, и приходит к выводу, что он верен. Подобным образом с 1282 года в Англии проверяют монеты, отчеканенные на Королевском монетном дворе. Этот процесс называется пробировкой и предполагает семплирование новых монет для проверки их единообразия.