Новые боги. Как онлайн-платформы манипулируют нашим выбором и что вернет нам свободу
Это исследование взбудоражило ученых по всему миру. Йилун Вонг и Михал Косински в своей работе прямо указывают на опасность злоупотребления подобным алгоритмом, ведь на свое лицо, в отличие от лайков и иных цифровых следов, человек никак повлиять не может.
Но что нам дают результаты этого весьма неоднозначного исследования? Интересную трактовку можно найти в блоге Блеза Агуэры-и-Аркаса. Он отмечает, что лицо человека может быть подвержено влиянию «духа времени» или модных тенденций, что, в свою очередь, могло бы дать информацию о сексуальной ориентации в исследовании. Итак, действительно ли компьютер предсказывал сексуальную ориентацию человека, руководствуясь именно формой лица? Вот что Агуэра-и-Аркас пишет о составных (то есть усредненных) изображениях из работы Вонга и Косински: «Среднестатистическая гетеросексуальная женщина использует тени для век, а среднестатистическая лесбиянка – нет. На гомосексуальном мужчине четче видны очки, на гомосексуальной женщине – в меньшей степени, в то время как на гетеросексуальных мужчине и женщине очков не видно вообще. Может ли быть так, что искусственный интеллект (алгоритм) определяет сексуальную ориентацию не по форме лица, а, скорее, по шаблонам, связанным с внешностью, выражением лица и образом жизни?» Кстати, для лучшего понимания замечаний Агуэры-и-Аркаса советую лично взглянуть на усредненные изображения (см. ссылку или оригинал статьи)[374].
На самом деле проблема машинного обучения заключается в том, что мы не знаем, чему именно учится искусственный интеллект. Эту неопределенность можно в некоторой степени уменьшить, сузив фокус исследования до конкретных характеристик. Мы с моим коллегой Джоном Д. Элхаи из Университета Толедо (США) недавно размышляли о том, как теоретическая надстройка, важная в психологии, может быть учтена в исследовательских проектах с применением машинного обучения[375]. Одна из опций – предоставить компьютеру только те данные, которые теоретически могут обладать диагностической силой для определенного фенотипа (например, сексуальной ориентации). В этом случае при анализе можно было бы уделить больше внимания вышеупомянутым внешним атрибутам моды и времени. В начале 2021 года механизм из описанных выше исследований был перенесен в политическую сферу (что, в общем-то, неудивительно). Михал Косински[376] опубликовал еще одну работу, в которой показал, что по фотографиям с лицами можно с некоторой вероятностью определить не только сексуальную, но и политическую ориентацию человека, а точнее, склонность к либеральным или консервативным взглядам (см. рис. 5.1). Известно, что в США белые, пожилые и мужчины более склонны к консервативному мышлению[377]. Интересно, что даже после того, как Косински проконтролировал эти факторы в своем анализе, ИИ все равно смог сделать предсказания о политической ориентации с точностью более 50 % (от 65 до 71 % в зависимости от выборки). То есть даже если не смотреть на такие очевидные характеристики, как пол, возраст или этническая принадлежность, изображения лиц содержат информацию, которая позволяет верно определить политические взгляды. Но что это за информация? К примеру, Косински заметил, что люди с либеральными взглядами чаще смотрят прямо в камеру. Кроме того, у них чаще встречается удивленное и менее недовольное выражение лица. Обобщая результаты, я собрал информацию из статьи Косински и отобразил на диаграмме, сравнивающей, насколько хорошо ИИ («алгоритм») и живые люди могут определить по фото политические взгляды, сексуальную ориентацию или характер. В целом, люди справляются с задачей лишь чуть лучше, чем подброшенная монетка. ИИ работает с точностью выше 50 %, но тоже далек от идеального результата.
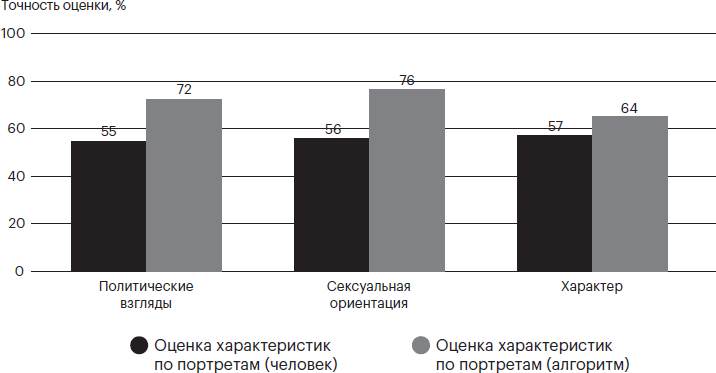
Рис. 5.1. Люди определяли политическую и сексуальную ориентацию, а также характер человека по фотографии с вероятностью чуть более 50 %. Точность прогноза заметно возрастает, если подключить машинное обучение (здесь – «алгоритм»). Цифры взяты из исследования Косински (2012; см. также примечание 31)
В завершение главы хотелось бы вспомнить простой принцип из информатики «Мусор на входе – мусор на выходе», иллюстрирующий ограничения, стоящие перед искусственным интеллектом (ИИ) в отношении оценки цифровых следов. Вообще, логично: если у вас плохие, «мусорные» данные, то и в результате ничего хорошего можно не ждать. Иными словами, минимальное требование для успешного применения ИИ – высокое качество данных. В примере с работой Йилуна Вонга и Михала Косински возникает закономерный вопрос: возможно ли вообще доказать, что фотографии лиц содержат какую-либо информацию о сексуальной ориентации их обладателей?
В целом, тема структуры данных занимает важное место в изучении ИИ. Об этом говорит в своей книге «Сверхдержавы искусственного интеллекта»[378] доктор Кай-Фу Ли, ведущий исследователь ИИ. Недавно он задался вопросом, какая из двух глобальных держав – США или Китай – выиграет гонку за более совершенный искусственный интеллект. Если вкратце, он утверждает, что Китай неизбежно опережает соперника по объему информации: 1,4 миллиарда китайцев попросту генерируют больше данных, чем около 330 миллионов американцев, особенно если учесть, сколько видеокамер установлено в Поднебесной и какой масштаб здесь приобрела цифровизация. По идее, те, у кого больше «хороших» данных, могут лучше обучить ИИ. На примере нескольких исследований, приведенных в этой книге, мы уже могли убедиться, что изучение или анализ больших объемов данных часто приводят к более надежным результатам. Китай, вероятно, будет лидером будущих разработок ИИ благодаря поддержке со стороны правительства, большому количеству специалистов, а также, не в последнюю очередь, особой культуре предпринимательства[379].
Глава 6. IT-компании манипулируют нами при помощи предварительной фильтрации контента?
Мы слышим эхо не только в горах, но и в ландшафте ежедневных новостей. Широко обсуждаемый феномен эхокамеры не нов и был известен задолго до цифровой эпохи: люди окружают себя той информацией, которая соответствует их мировоззрению. В такую эхокамеру легко попасть, например, если предпочитать один источник новостей, будь то газета
Но эхокамера возникает не только когда мы регулярно читаем одну и ту же ежедневную газету и ничего кроме. Компания завсегдатаев в кафе, которая за столиком сокрушается о политике Ангелы Меркель в отношении коронавируса, тоже может стать эхокамерой – ведь они подтверждают взгляды друг друга. Так что нет ничего удивительного в том, что в исследованиях в сфере политологии и массмедиа уже многие годы говорят об отрицательном влиянии эффекта эхокамеры на политический дискурс.
Прежде чем подробно остановиться на негативном воздействии этого феномена, давайте поговорим о смежном понятии – пузыре фильтров. Этот термин получил известность благодаря книге Эли Паризера «За стеной фильтров. Что интернет скрывает от вас?» («The Filter Bubble: What the Internet Is Hiding From You»)[380] и иллюстрирует, что происходит, когда технологические компании радикально фильтруют информацию. Пузырь фильтров возникает, когда на онлайн-платформах отображается только тот контент, который соответствует цифровым следам пользователя. Как и в случае с эффектом эхокамеры, люди будут сталкиваться в социальных сетях и поисковых системах исключительно с новостями и постами, соответствующими их мировоззрению. Подобная предварительная фильтрация – обычная практика для IT-гигантов: ленты подвергаются алгоритмической обработке, чтобы лучше соответствовать интересам пользователя. Но, к сожалению, не все об этом знают.
Попробуем сопоставить понятия эхокамеры и пузыря фильтров. Для начала отметим, что первая появилась гораздо раньше. Как я уже описывал в примере выше, читатель
Пользователь может
Напомню, что формирование персонализированной ленты новостей выгодно технологическим корпорациям, так как это хороший способ увеличить время пребывания пользователей на онлайн-платформе (см. главу 3). В конечном счете, оказавшись внутри пузыря фильтров или же в эхокамере, мы слышим лишь отзвуки нашего собственного мировосприятия. Отчасти за это ответственны мы сами: ведь мы создаем эхокамеру вокруг себя, а наши друзья, как правило, разделяют наши взгляды и интересы (позже мы поговорим о социальной гомофилии). Но одновременно с этим эхокамера может быть выстроена технологическими корпорациями[382]. Я убежден, что необходимо знать и понимать, как это работает, чтобы сделать первый шаг к победе над ними.
Технологические компании начали предварительно фильтровать контент совсем недавно. В книге «Обезьяний хаос в Кремниевой долине» («Chaos Monkeys: Obscene Fortune and Random Failure in Silicon Valley») бывший сотрудник Facebook Антонио Гарсиа Мартинес рассказывает о том, как еще во время онбординга[383] в апреле 2011 года впервые столкнулся с мыслью, что фейсбук, ставший сегодня самой влиятельной социальной сетью в мире, все больше превращается в персонализированную газету. В тот момент полным ходом шел процесс соответствующей трансформации платформы: если в 2004 году социальная сеть выглядела скорее как список друзей, то уже в 2006-м была представлена мини-лента, а в 2011-м появилась хроника, отображающая историю жизни пользователя (см. статью Люка Манна и информацию на фейсбуке)[384]. В своей книге Антонио Гарсиа Мартинес метко описывает эту идею как «твой личный
Критерии отбора новости для ленты:
Итак, что же скрывается за элементами этой формулы?
Переменная «Автор публикации» учитывает, насколько важен и близок для вас человек, разместивший пост. Как часто автор публикации контактирует с владельцем ленты новостей на фейсбуке? Логично, что сообщения от тех людей, с кем мы чаще общаемся, имеют больше шансов оказаться в нашей ленте.
Переменная «Популярность сообщения» используется для расчета того, какой отклик получил пост/комментарий: если у поста много лайков и репостов, фейсбук покажет вам его с большей вероятностью.
Переменная «Тип публикации», как и переменная «Автор публикации», учитывает историю действий пользователя. Она используется в формуле для определения типов постов, которые предпочитает пользователь (может, он охотнее просматривает изображения, чем тексты или видео; или политические новости стали для него интереснее, чем развлечения, и т. д.).